Solusi Cerdas Mahasiswa S1 Teknik Elektro UNESA untuk Klasifikasi Ujaran Kebencian Menggunakan Multiclass NLP (BI-LSTM) Pada Program MSIB Batch 6 Bersama PT. Hacktivate Teknologi Indonesia
Studi Independen Bersertifikat batch 6 merupakan salah satu program unggulan dari Kampus Merdeka yang memberikan kesempatan kepada mahasiswa untuk mendapatkan pengalaman praktis dan sertifikasi profesional di bidang teknologi. Salah satu penyelenggara program ini adalah PT. Hacktivate Teknologi Indonesia, yang terkenal dengan pendekatan pembelajaran yang inovatif dan relevan dengan kebutuhan industri.
PT. Hacktivate Teknologi Indonesia adalah perusahaan yang bergerak di bidang pendidikan teknologi, berfokus pada pengembangan keterampilan digital melalui program bootcamp, kursus online, dan proyek-proyek kolaboratif. Dengan pengajar yang berpengalaman dan kurikulum yang selalu diperbarui, Hacktiv8 berkomitmen untuk mencetak talenta digital siap kerja yang mampu bersaing di era industri 4.0.

Gambar 1. Indeks Pengguna Aktif Sosial Media
Salah satu tugas akhir menarik yang dihadapi oleh peserta Studi Independen Bersertifikat bersama PT. Hacktivate Teknologi Indonesia adalah proyek "KLASIFIKASI TWEET UJARAN KEBENCIAN DENGAN MULTICLASS NLP (BI-LSTM)". Proyek ini merupakan tantangan yang relevan dengan perkembangan teknologi dan kebutuhan masyarakat untuk mengatasi isu ujaran kebencian di media sosial ujar Muhammad Arfian Alfi Rachmadhani sebagai mahasiswa peserta msib dari Prodi S1 Teknik Elektro UNESA.
Ujaran kebencian di media sosial merupakan masalah serius yang dapat memicu konflik dan merusak keharmonisan sosial. Oleh karena itu, diperlukan teknologi yang mampu mendeteksi dan mengklasifikasikan ujaran kebencian secara otomatis. Natural Language Processing (NLP) dengan pendekatan Bi-LSTM (Bidirectional Long Short-Term Memory) adalah salah satu metode yang efektif untuk menangani tugas ini.
Tujuan utama dari proyek ini adalah membangun model machine learning yang mampu mengklasifikasikan tweet yang mengandung ujaran kebencian ke dalam beberapa kategori, seperti:
Rasisme
Seksisme
Fanatisme
Kategori kebencian lainnya
Dengan menggunakan pendekatan multiclass classification, diharapkan model ini dapat memberikan hasil yang akurat dan membantu dalam upaya moderasi konten di platform media sosial.
Proyek ini melibatkan beberapa tahap utama, yaitu: pengumpulan data, prapemrosesan data, model arsitektur, validasi dan evaluasi.
Pengumpulan data

Gambar 2. Datasheet Tweet
Gambar 2. merupakan datasheet tweet yang mengandung berbagai kategori ujaran kebencian. Dimana data tersebut diperoleh dari jurnal yang berjudul “Multi-label Hate Speech and Abusive Language Detection in Indonesian Twitter”. Data tersebut mencakup ribuan tweet yang terdistribusi ke dalam beberapa kategori ujaran kebencian.
Pra-Pemrosesan Data

Gambar 3. Hasil Cleaning Data
Data yang dikumpulkan mengalami berbagai tahap pra-pemrosesan untuk meningkatkan kualitasnya. Membersihkan dan mempersiapkan data untuk analisis lebih lanjut, termasuk tokenisasi, stemming, dan penghapusan stopwords.
Model Arsitektur

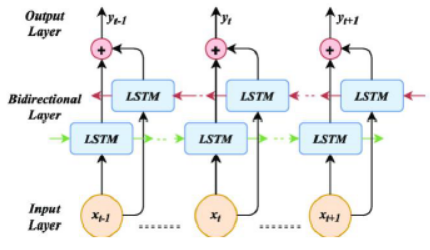
Gambar 4. Arsitektur Bi-LSTM
Model architecture Ini mencakup pilihan mengenai jenis model, jumlah lapisan, jumlah unit di setiap lapisan, fungsi aktivasi, dan lain-lain. Bidirectional Long Term Short Memory (Bi-LSTM) merupakan turunan dari algoritma LSTM yang merupakan bagian dari RNN.
Gambar 4. menunjukkan bahwa Bi-LSTM memiliki dua layer LSTM, satu layer bertanggung jawab untuk memproses data input, dan layer dua bertanggung jawab untuk mempropagasi balik hasil dari layer input.
Validasi dan Evaluasi

Gambar 5. Hasil Prediksi Model
Menguji model dengan data uji dan mengevaluasi kinerjanya menggunakan metrik seperti akurasi, presisi, recall, dan F1-score. Dari hasil tersebut dapat disimpulkan bahwa model mempunyai performa yang cukup baik dalam memprediksi kelas weak hatespeech dengan nilai F1-score yang cukup baik. Sedangkan untuk nilai moderate dan strong, model masih belum bisa melakukan prediksi secara baik, dibuktikan dengan nilai score F1-score pada masing-masing kelas yang berada pada nilai dibawah 70%.
Dosen pembimbing lapangan, Ibu Dr. Lusia Rakhmawati berharap dengan selesainya proyek ini mahasiswa mempunyai pengalaman nyata dalam membuat sistem yang efektif dalam mengidentifikasi dan mengklasifikasikan ujaran kebencian di media sosial. Selain itu, peserta yang terlibat dalam proyek ini akan mendapatkan pengalaman berharga dalam menerapkan teknologi NLP dan machine learning dalam konteks dunia nyata.